Advanced Event Management Using opEvents
I have received some questions lately regarding how our systems deal with events and major outages. Dependent on your resolution environment you may call this a range of things such as hierarchical event management, deduplicating events or even weathering event storms. Regardless of the verbiage, the concept is the same: if a device is down, does your event management system send multiple notifications about dependent nodes also being down? opEvents handles these events in an incredibly simple method, using stateful deduplication and event correlation.
Stateful Deduplication
opEvents uses stateful deduplication to ensure that only one event has been created for one instance of a state. For example, if a node is registered as down, polled later and still down, this will not generate two events -- it will only be considered a single event. This is dependent on the current state still being registered as down and the node is not considered in a flap window. A flap is considered to be in effect if a node is going up and down inside a given window (default 90 seconds); this will help reduce the overall event notifications while still ensuring correct faults are recorded.
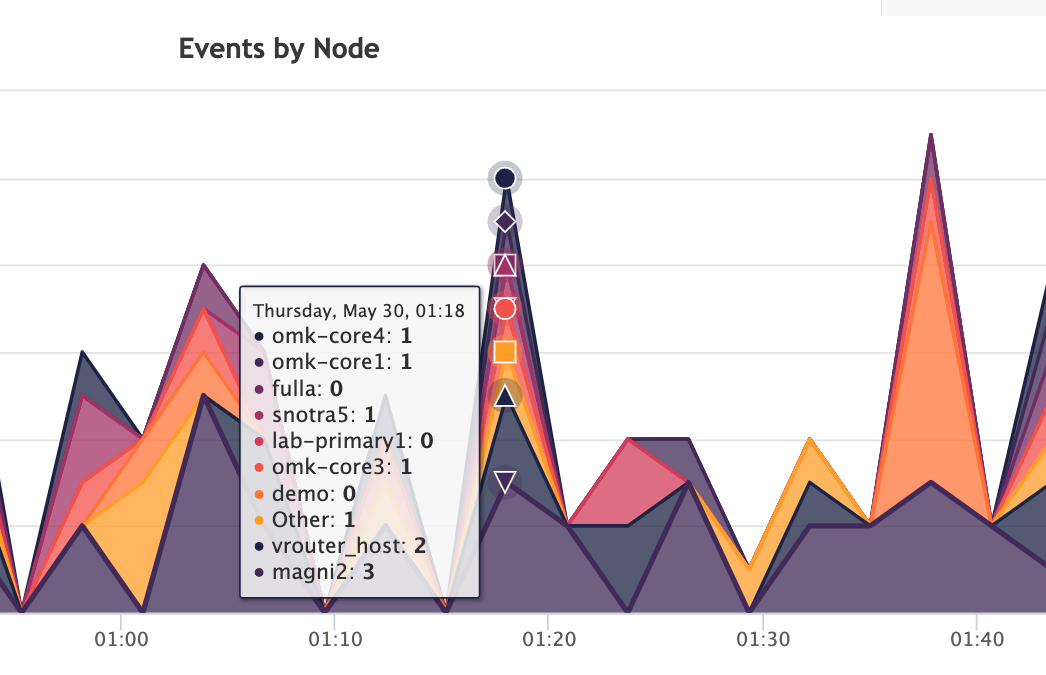
Event Correlation
The power of opEvents is encapsulated in how it handles event correlation. There is a point in fault management where a network engineer would prefer the right information compared to all the information. Event Correlation uses this principle to do some of the heavy-lifting for you and give you the information that is most relevant to a problem. A synthetic event can be generated that will process correlated events, based on location or dependency, for example, group these together and only one event is triggered. This will aid in diagnostics of faults, but also reduce the number of triggered events if a location is down.
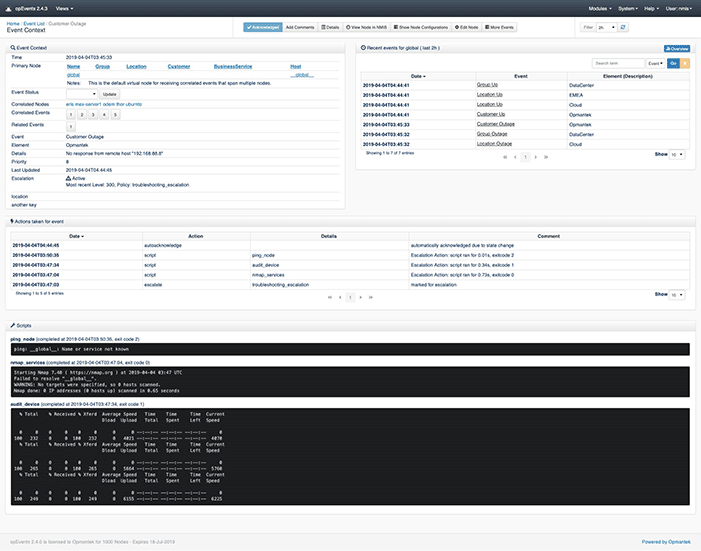
The combination of these two principles can help reduce the time to detecting root cause while maintaining a vigilant watch over your network. If you can shape your event management with these principles, you will be getting the best information for you to do your job, without the extra noise. A little investment in this process will save you considerably in the long run.
As always our Community Wiki has detailed walkthroughs regarding how to implement these concepts:
- Event Correlation
- Event Correlation based on location
- Deduplication and storm control in opEvents
As well as some incredibly helpful webinars about these topics:
- Performance and Fault Management for MSP and Enterprise Level Businesses
- Configuring Event Escalation and Notifications
- Intelligent Fault and Configuration Management
If you have questions regarding any topics, have a feature request or any feedback, don't hesitate to contact us.
Related reading: Network Automation for Configuration and Change Management