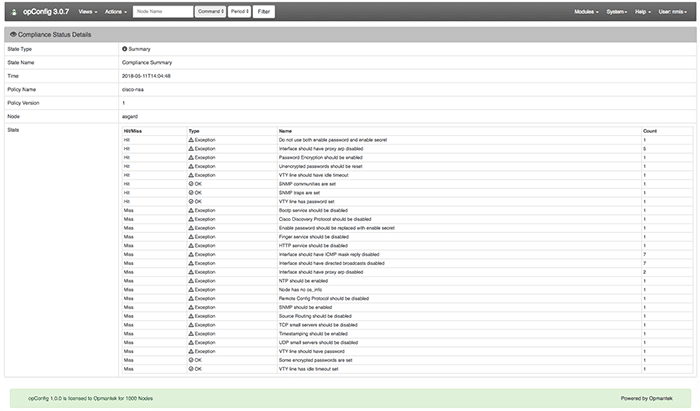
NMIS es una herramienta poderosa nada más sacarla de la caja, sin embargo, si se toma el tiempo necesario para entender todo lo que realmente es capaz de hacer, se puede personalizar para que se adapte a casi cualquier proceso de Gestión de Redes. Una característica útil que los usuarios de NMIS pueden desconocer es la capacidad de crear Tablas Personalizadas. Esta guía le llevará paso a paso con un ejemplo del mundo real para ayudar a que su red funcione para usted.
Paso 1. Cree una nueva configuración de tabla NMIS.
For each known type of table there is a separate table configuration file all of which are named Table-<tableName>.nmis (e.g for the table Nodes.nmis the configuration file is called Table-Nodes.nmis). Both of these tables and their configuration files are located in the conf directory – /usr/local/nmis8/conf. The benefit of NMIS being open-source, is that this code can be modified and customized to display any information you reqquire. For this example we are going to create a Service Level Agreement (SLA) table to be able to assign devices to specific SLA levels (Bronze, Silver, Gold). Below is an example of what our new file Table-SLA.nmis will look like.
%hash = (
SLA => [{
Service_Level => {
header => ‘Service Level’,
display => ‘popup,header’,
value => [“Gold”, “Silver”, “Bronze”] }},
{ Email => {
header => ‘Email Address’,
display => ‘key,header,text’,
value => [“”] }},
{ Name => {
header => ‘Name’,
display => ‘header,text’,
value => [“”] }},
]
);
Para que entiendas lo que muestra este código, lo dividiremos en algunas secciones:
SLA => – This is the name of the table and it should match the naming convention from the filename, Table-<tableName>.nmis.
Service_Level => - Cada columna de la tabla se define con una entrada similar a ésta. En este caso la columna se llamaría Nivel_de_servicio. Para terminar de definir la columna los siguientes campos necesarios son los de cabecera, visualización y valor.
header => - Muestra lo que se mostrará cuando se vea la tabla. En este ejemplo se mostraría "Nivel de servicio".
display => 'key, header, text, popup' - header indica si debe estar en la cabecera o no, y text indica qué tipo de caja de entrada utilizar. Esta sección también incluye la clave, que se incluye como clave primaria si es necesario. La opción de visualización del popup hace una caja de selección de un solo valor, esto es equivalente a un elemento de formulario HTML "select". Este ejemplo muestra estos tres niveles de servicio como una visualización "popup".
valor => - Muestra cuál es el valor por defecto o la lista de selección. En este ejemplo, el valor se establecerá en Oro, Plata o Bronce, dependiendo del nivel de servicio.
Ahora que se entiende cómo se construye el código, se puede ver que la siguiente sección, Correo electrónico utiliza un encabezado de 'Dirección de correo electrónico'. Se muestra utilizando las opciones de visualización de clave, cabecera o texto. Observe que el valor se establece en comillas vacías, esto es porque el usuario introducirá la dirección de correo electrónico utilizando el teclado o la pantalla de `texto`. La sección de código "Nombre" tiene un formato similar al de la dirección de correo electrónico.
Paso 2. Añada la tabla a Tables.nmis.
Una vez creado el archivo de configuración de la tabla(Table-SLA.nmis en este caso), es necesario añadir la tabla al archivo Tables.nmis. Este archivo enumera todas las tablas que se envían con NMIS, así como las tablas personalizadas que se añaden. Este siguiente paso puede realizarse fácilmente utilizando la interfaz gráfica de usuario de NMIS.
Para ello, vaya a la barra de menú de NMIS y seleccione Sistema -> Configuración del sistema -> Tablas. Una vez que aparezca el menú Tablas, en la esquina superior derecha de la tabla debería ver Acción > añadir. Introduzca las propiedades de la tabla, el nombre de la tabla debe coincidir con el nombre en la Configuración de la Tabla (SLA en nuestro caso). El "Display Name" es lo que quieres que aparezca en el menú y el campo Description es para recordar lo que hace la Tabla. Una vez hecho esto, actualice el Tablero NMIS y verá su nueva tabla en la tabla de Tablas. Todavía no podrá acceder a su tabla, esto se debe a que no se han definido los permisos para la misma.
Paso 3. Cree los permisos en Access.nmis.
Para que la tabla muestre información, es necesario darle permisos de acceso en NMIS. Hay un script que se creó para hacer precisamente esto. Ejecute el siguiente script para añadir permisos por defecto a la tabla recién creada:
/usr/local/nmis8/admin/add_table_auth.pl SLA
La parte SLA al final del script es, por supuesto, el nombre de la tabla. Debería ver un mensaje una vez que se ejecute el script diciendo
Checking NMIS Authorization for SLA INFO: Autorización NO definida para SLA RW Access, AÑADIRLA AHORA
así como otro mensaje similar para el acceso a la vista. Este script se puede ejecutar varias veces, si ejecuta el script de nuevo no añadirá la tabla dos veces, sin embargo, le permitirá saber si los permisos se han creado para la tabla en particular.
Paso 4. Añade los datos a tu tabla.
Una vez que se han dado los permisos correctos a la tabla, es hora de añadirle una entrada de datos. Actualice el panel NMIS y navegue hasta su tabla - Sistema -> Configuración del Sistema -> SLA para el ejemplo actual. Es probable que aparezca un mensaje de error la primera vez que haga esto y es porque todavía no hay datos en la tabla.
Para añadir datos a la tabla, haga clic en Acción > Añadir. Introduzca un nombre, un nivel de servicio y un correo electrónico y haga clic en Añadir para guardarlo. Ahora, cuando abra la tabla, debería ver esta información completada. Esta información se almacena en /usr/local/nmis8/conf/SLA.nmis para el ejemplo actual. Si lo desea, puede añadir a este archivo utilizando el mismo formato que la primera entrada, si no desea utilizar la interfaz gráfica de usuario, ambos métodos funcionan. Eso es todo, ¡su nueva tabla SLA personalizada está creada! Puede crear tantas tablas como necesite y puede tomar el control del flujo de trabajo de su equipo. Estas tablas personalizadas son útiles en NMIS pero también se pueden utilizar en otros módulos de Opmantek como opCharts.
Uso de su tabla NMIS personalizada en opCharts
Si desea visualizar la tabla SLA o cualquier otra tabla creada dentro de las tablas de opCharts, existe una función que permite eliminar o añadir columnas de la tabla según se desee. Esta función está disponible para las versiones 3.2.2 y posteriores de opCharts. Una nota importante antes de comenzar es que las únicas vistas que soportan columnas personalizadas por el momento son la vista de Interfaces, la vista de Nodos, la vista de Apagones Programados y la vista de Contexto de Nodo o Widget de Información de Nodo.
Paso 1. Edite el archivo de configuración deseado para la vista correspondiente.
Una nota de precaución antes de cambiar nada, habilite esta función con cuidado, cuando actualice opCharts tendrá que vigilar de cerca ya que las tablas y las propiedades de los nodos pueden cambiar entre versiones. La actualización de opCharts puede romper la funcionalidad de una configuración de tabla personalizada. Si utiliza esta función, se recomienda actualizar en un entorno de prueba antes de actualizar su entorno de producción.
Habilitación de la función
Para habilitar esta función hay que hacer lo siguiente.
- Crear un directorio llamado /usr/local/omk/conf/table_schemas
- Copie el archivo de configuración de la vista específica que requiere modificación de /usr/local/ omk/lib/json/opCharts/table_schemas/ en /usr/local/omk/conf/table_schemas.
Nota - Sólo los archivos JSON necesarios deben ser copiados al directorio /usr/local/omk/conf/table_schemas ya que tener archivos de configuración innecesarios en este directorio puede hacer que las futuras actualizaciones sean impredecibles.
Dicho esto, cada vista tiene un archivo de configuración independiente. Dependiendo de la vista de opCharts a la que desee añadir su tabla NMIS SLA o cualquier otra tabla, deberá editar el archivo correspondiente. A continuación encontrará una lista de los nombres de los archivos dependiendo de la vista en la que desee mostrar su tabla:
Vista de interfaces - opCharts_interface-list.json
Vista de nodos - opCharts_node-list.json
Interrupciones programadas - opCharts_outage-schema.json
Contexto del nodo - opCharts_node-summary-table.json
For our example, we are going to be using the Nodes View or opCharts_node-list.json. Start by editing the file with your favorite text editor – vi /usr/local/omk/conf/ table_schemas/opCharts_node-list.json .
Once you open the file you will notice it is formatted into a list of the tables already shown in opCharts Nodes view. The order that these sections of code are in determines the order the tables will be displayed. This means you can have your custom table in any order you wish, further, you can remove unwanted parts of a table by removing the entry from this file. For the sake of this example, I will be adding our NMIS SLA table to the bottom of this file causing it to display at the end of the row of tables. The entry for the SLA table should be similar to the following below:
{
“name”: “configuration.SLA”,
“label”: “Service Level”,
“cell”: “String”
}
The “name” section is the name of the node property and requires you to call the intended configuration file which in our case is the configuration file we created (SLA.nmis). The “label” section of code is what text will be displayed in the table column. “Cell” is the cell type and typically is left as “string”.
Paso 2. Actualice la página de opCharts
Una vez editado el archivo, guárdelo, compruebe si hay errores de sintaxis y actualice la página web de opCharts. No es necesario reiniciar ningún demonio. Cuando la página se haya recargado, debería ver su nueva columna mostrada en la tabla. La tabla se muestra, sin embargo, no hay datos poblados todavía. Para que los datos aparezcan tenemos que modificar algunos archivos más.
Filtrado de nodos por atributos en NMIS/opCharts
Ahora que tiene su tabla de Niveles de Servicio en opCharts, ¿qué pasaría si quisiera utilizar la función de filtro de opCharts para mostrar sólo los dispositivos con un Nivel de Servicio Oro, por ejemplo? Esto se puede lograr haciendo unos pocos cambios rápidos.
Paso 1. Modifique la Tabla-Nodos.nmis.
Comience por editar el archivo Table-Nodes.nmis ubicado en /usr/local/nmis8/conf/Table-Nodes.nmis. Para este ejemplo, vamos a añadir nuestro campo de Nivel de Servicio.
Inserte el nuevo campo entre la entrada 'extra_options' y la entrada 'advanced_options'. Puede elegir dónde quiere que se muestre en NMIS, pero si sigue esta guía se mostrará debajo de la sección Extra Options en la tabla Nodes de NMIS.
El código en negrita a continuación muestra un ejemplo de dónde elegí insertar la tabla SLA. Esta sección es similar al diseño de nuestro archivoTable-SLA.nmis con una diferencia clave, la regla de validación añadida 'onefromlist'. Esta regla indica que el valor de la propiedad debe ser uno de los valores explícitos dados (Bronce, Plata, Oro), o uno de los valores de visualización por defecto si no se dan otros valores en esta regla.
{
netType => {
header => 'Tipo de red',
display => 'popup',
value => [ split(/\s*,\s*/, $C->{nettype_list}) ],
validate => { "onefromlist" => undef } }},
{
ubicación => {
header => 'Ubicación',
display => 'header,popup',
value => [ sort keys %{loadGenericTable('Ubicaciones')}],
validate => { "onefromlist" => undef } }},
{
SLA => {
header => 'Nivel de Servicio',
display => 'header,popup',
value => ["Oro", "Plata", "Bronce"],
validate => { "onefromlist" => undef } }
},
Paso 2. Compruebe que su tabla se está representando correctamente
Acceda a la GUI de NMIS y en el menú superior vaya a Sistema -> Configuración del sistema -> Nodos NMIS. Si los pasos fueron correctos se mostrará una columna de "Nivel de Servicio".
Paso 3. Modificar Config.nmis
Abra y edite el archivo Config.nmis con su editor de texto favorito. Este archivo se encuentra en
/usr/local/nmis8/conf/Config.nmis . Añade el nombre de la tabla (SLA) en la lista siguiendo el formato de las otras entradas. A continuación se muestra un fragmento del aspecto de este código utilizando nuestro ejemplo:
'node_summary_field_list' => 'host,uuid,customer,businessService,SLA,serviceStatus,snmpdown,wmidown,
remote_connection_name,remote_connection_url,host_addr,location',
Paso 4. Modificar opCommon.nmis
Add the new field to the opcharts_node_selector_sections in opCommon.nmis. The opCommon.nmis file is located at /usr/local/omk/conf/opCommon.nmis Follow the format of the code already present adding a new section for our Service Level table ‘SLA’. A snippet of what this code may look like is below:
‘opcharts_node_selector_sections’ => [
{
‘key’ => ‘nodestatus’,
‘name’ => ‘Node Status’
},
{
‘key’ => ‘group’,
‘name’ => ‘Group’
},
{
‘key’ => ‘roleType’,
‘name’ => ‘Node Role’
},
{
‘key’ => ‘SLA’,
‘name’ => ‘SLA’
},
Step 5. Verify the changes worked properly.
Después de realizar los cambios en el archivo opCommon.nmis, asegúrese de guardarlos y luego realice un reinicio del servicio omkd - service omkd restart. Una vez reiniciado el servicio, abra un navegador y navegue a la vista de Nodos en opCharts. El nuevo campo debería aparecer en la tabla, así como en el menú Filtro de nodos de la izquierda. Si sigue este ejemplo, debería aparecer la posibilidad de filtrar por SLA. Simplemente haga clic en el filtro y elija el
Nivel de Servicio y los nodos deberían ser filtrados dependiendo del nivel de servicio que se les haya asignado.
Conclusión
Los entornos de red son muy diferentes, al igual que sus ingenieros de red, lo que cambia significativamente la información que es importante reportar. NMIS y opCharts, así como los otros módulos de Opmantek, permiten increíbles niveles de personalización, dan la posibilidad de reportar la información que le conviene.
Para obtener más información sobre NMIS y opCharts y todas sus funciones, visite nuestro sitio web o envíenos un correo electrónico a contact@opmantek.com.