
Obtener soporte en FirstWave - Para clientes
Gracias por contactar con Soporte de FirstWave.
Para que le ayudemos a crear un caso, necesitará:
Para cualquier ayuda o consulta, póngase en contacto con nosotros en
support@firstwave.com.
Gracias por contactar con Soporte de FirstWave.
Para que le ayudemos a crear un caso, necesitará:
Para cualquier ayuda o consulta, póngase en contacto con nosotros en
support@firstwave.com.

A medida que las empresas confían cada vez más en sistemas distribuidos y microservicios para dar servicio a sus crecientes redes, la comunicación eficaz entre sus distintos componentes se convierte en un reto cada vez mayor.
Introduzca el bus de mensajes o bus de servicios empresariales: un sistema de comunicación que permite el intercambio de datos sin fisuras entre los componentes de la red para ayudarle a gestionar su red distribuida.
En este blog, desglosaremos el concepto de una arquitectura de bus de mensajes, explicando cómo funciona, sus características principales, las alternativas disponibles y los beneficios que una solución de bus de mensajes como FirstWave opHA-MB aporta a los sistemas distribuidos.
Imagine una ciudad bulliciosa con numerosos barrios, cada uno de los cuales representa una aplicación o servicio diferente. Para que la ciudad funcione sin problemas, estos barrios necesitan intercambiar información de forma eficiente.
Un autobús de mensajes actúa como el sistema de tránsito central de la ciudad, garantizando que los mensajes lleguen a los destinos correctos sin necesidad de conexiones directas entre ellos. En términos técnicos, el bus de mensajes permite que distintas aplicaciones, servicios o sistemas se comuniquen transmitiendo mensajes a través de una infraestructura compartida.
Esta configuración garantiza que cada componente siga siendo independiente para ofrecer flexibilidad y escalabilidad.
1. Productores (pollers)
También conocidos como peers, los pollers recopilan datos de varios dispositivos y sistemas de red, generando mensajes que contienen información crítica sobre el rendimiento, los eventos y los estados de la red. Estos sondeadores pueden escalarse horizontal o verticalmente para recopilar datos de forma eficiente en redes extensas.
2. Broker (bus de mensajes)
El bus de mensajes, que actúa como núcleo central de comunicación, garantiza la sincronización en tiempo real entre varios encuestadores. Gestiona el encaminamiento de mensajes de los productores a los consumidores, manteniendo la integridad de los datos mediante la replicación de mensajes en tres nodos, lo que permite al sistema tolerar fallos de un solo nodo.
3. Consumidores (servidor primario y aplicaciones)
El servidor primario y las aplicaciones asociadas funcionan como consumidores. Reciben y procesan los mensajes transmitidos por el bus de mensajes, proporcionando a los usuarios una visión consolidada y en tiempo real del estado y el rendimiento de la red. Esta configuración mejora funciones como el registro de eventos, la supervisión y la generación de cuadros de mando e informes intuitivos.
Un bus de mensajes desacopla la comunicación, permitiendo que emisores y receptores operen de forma independiente para que la comunicación en red se produzca de forma asíncrona. Esto significa que los usuarios pueden gestionar sistemas de red distribuidos a través de un punto central que estandariza estilos de comunicación dispares. El resultado: un sistema sencillo e integrado.
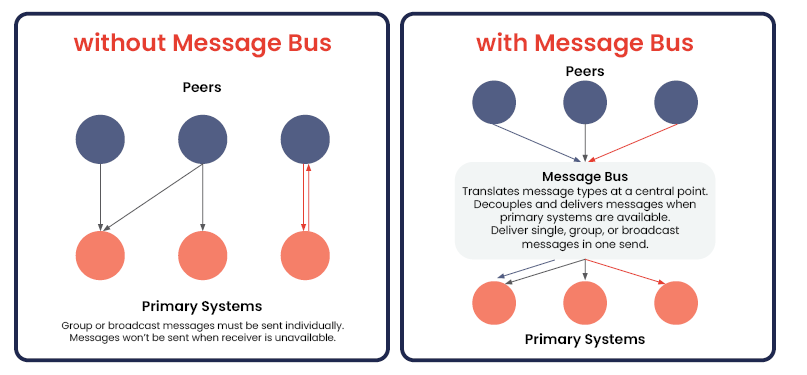
Una arquitectura de bus de mensajes es útil para las empresas que gestionan redes a gran escala, distribuidas, con múltiples clientes y/o de misión crítica, ya que los datos están disponibles libremente para viajar entre los puntos finales según sea necesario.
En los entornos modernos de gestión de redes y ciberseguridad, diferentes servicios gestionan funciones distintas -como la supervisión de redes, las alertas de seguridad, los análisis de rendimiento y los flujos de trabajo de automatización- al tiempo que se comunican entre sí sin problemas. Un buen bus de mensajes actúa como columna vertebral de esta comunicación, garantizando que los servicios sigan estando poco acoplados, sean escalables y resistentes en arquitecturas distribuidas.
Entre las ventajas de la gestión de redes para microservicios se incluyen:
Las aplicaciones modernas recurren al procesamiento de eventos en tiempo real para mejorar la capacidad de respuesta y la automatización. Un bus de mensajes es un componente básico de las arquitecturas basadas en eventos, en las que los eventos (por ejemplo, acciones del usuario, cambios en el sistema o activadores externos) se publican y consumen de forma dinámica.
Dónde es útil:
Las alternativas a un bus de mensajes suelen basarse en la comunicación punto a punto, en la que los servicios se comunican directamente en lugar de a través de un punto central interconectado.
La comunicación punto a punto tiene sus ventajas, pero limita sus capacidades en el sentido de que aísla los datos entre emisor y receptor, impidiendo la comunicación cruzada que puede limitar la eficacia en arquitecturas más complejas.
Pero la buena noticia es que no está limitado a una sola opción; su sistema distribuido puede utilizar una combinación de estilos de comunicación para diferentes funciones con el fin de optimizar su eficacia para su empresa.
Las API son una solución estrechamente acoplada en la que cada uno de sus servicios necesita conocer cada uno de sus puntos finales. Con las API, cada servicio gestiona sus propias conexiones. Este enfoque es ideal para arquitecturas más sencillas o cuando la latencia no es una consideración importante.
Pros:
Contras:
Una cola de mensajes es similar a un bus de mensajes, pero difieren en la forma en que se enrutan y procesan los mensajes. A diferencia de un bus de mensajes, una cola de mensajes utiliza la comunicación punto a punto y los mensajes se priorizan por el primero en entrar, primero en salir. Una vez consumido, el mensaje simplemente se elimina de la cola.
Pros:
Contras:
Si dispone de tiempo para implementarlos y gestionarlos todos de forma eficiente, puede utilizar un bus de mensajes junto con otros métodos de comunicación para ampliar el alcance de sus funciones y optimizar su configuración para diferentes casos de uso.
Por ejemplo, además de la solución opHA Message Bus de FirstWave, también proporcionamos API para permitir la transferencia de mensajes, así como la integración con agentes de mensajes basados en colas como RabbitMQ, todo ello combinado con la asistencia práctica de expertos para facilitar la implementación.
Para ayudarle a elegir el mejor diseño (o combinación de diseños) para su empresa, hágase las siguientes preguntas:
opHA Message Bus (opHA-MB) es la solución de bus de mensajes propia de FirstWave, que le permite simplificar la gestión de sus sistemas de red distribuidos con transferencia de datos en tiempo real a través de entornos diversos y multi-tenanted.
Esta solución avanzada de gestión de redes actúa como el sistema nervioso central de su red para ayudarle a mantener un rendimiento óptimo de la red, garantizar la resistencia y resolver rápidamente los problemas derivados de una infraestructura de red compleja.
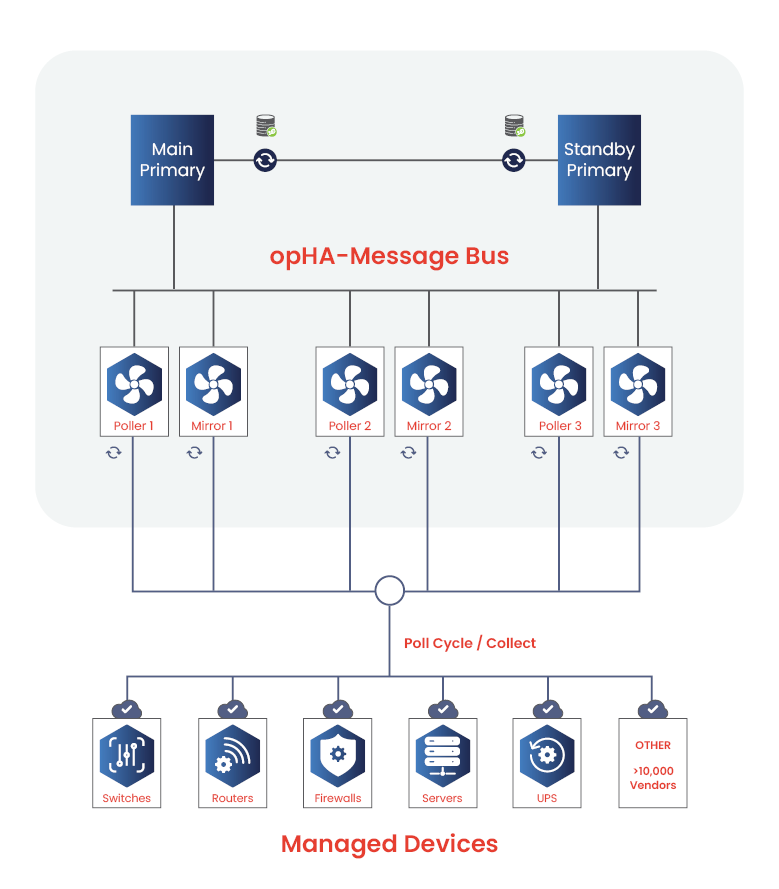
Al mantener desacoplados a productores y consumidores, esta arquitectura permite que cada componente funcione de forma independiente. Esto mejora la flexibilidad, la escalabilidad y la resistencia, garantizando una gestión eficaz de la red incluso a medida que crece la demanda.

Al activar la función de operador virtual en el módulo opConfig de NMIS, los responsables de TI pueden capacitar a su equipo para abordar de forma proactiva los problemas habituales de la red, garantizando un rendimiento, una seguridad y un cumplimiento óptimos.
El operador virtual puede:

Evolución de las operaciones de red: de manuales a virtuales
El panorama de las operaciones de red ha experimentado una transformación radical.
Tradicionalmente, la gestión de redes implicaba un enfoque predominantemente manual, que dependía en gran medida de la experiencia y la intervención humanas para resolver problemas, configurar dispositivos y garantizar un rendimiento óptimo. Los errores humanos, la lentitud de los procesos y la incapacidad de escalar eficazmente ante la creciente complejidad de la red planteaban importantes retos a las prácticas tradicionales de gestión de redes.
En la última década, las plataformas de supervisión y gestión de redes se han vuelto más inteligentes, con avances en big data que proporcionan una mayor comprensión del entorno de red, cómo y cuándo se accede a él, qué dispositivos se utilizan y cuándo, qué servicios funcionan de forma óptima y qué servicios se están degradando.
Según la Guía de mercado para la automatización de redes de Gartner, mientras que más del 65% de las actividades de red de las PYME se realizan manualmente, un porcentaje cada vez mayor de grandes empresas automatiza más de la mitad de sus actividades de red.
Firstwave Cloud Technology ha estado a la vanguardia de esta nueva era de inteligencia artificial, recopilando y analizando datos de red para proporcionar detección avanzada de anomalías y análisis predictivos que permiten a los operadores gestionar de forma proactiva la infraestructura y los dispositivos para garantizar un entorno de red saludable y predecible.
Con la introducción del Operador Virtual, esta inteligencia de máquina va un paso más allá, permitiendo a la plataforma NMIS tomar medidas en función de los conocimientos y permitiendo a los operadores programar una serie de actividades que el operador puede realizar con sólo pulsar un botón.
Este artículo profundiza en el concepto de operador virtual y explora sus ventajas y su impacto potencial en la estrategia de automatización de redes de una organización. Examinaremos cómo la automatización, a través de la implementación de un operador virtual, está reimaginando la administración de la red, impulsando la eficiencia, mejorando la seguridad y desbloqueando nuevos niveles de rendimiento y conocimientos.
¿Qué es el Operador Virtual?
El Operador Virtual es un agente de software diseñado para automatizar tareas repetitivas, optimizar el rendimiento de la red y proporcionar información inteligente. Funciona como un motor basado en reglas que aprende de los datos históricos, las configuraciones de red y las mejores prácticas, lo que le permite tomar decisiones informadas y emprender acciones proactivas para mantener la estabilidad y la eficiencia de la red.
Piense en un Operador Virtual como un asistente de IA altamente especializado y adaptado a la administración de redes. Actúa como una extensión del equipo de red, asumiendo las tareas mundanas y repetitivas, liberando a los ingenieros humanos para que se centren en retos más estratégicos y complejos.
Ventajas de implantar una Operadora Virtual
La implantación de un Operador Virtual ofrece varias ventajas clave a los equipos de administración de redes:
Al automatizar las tareas rutinarias, el Operador Virtual puede liberar a los ingenieros para que se centren en retos más estratégicos y complejos. Este cambio permite a los equipos aprovechar al máximo el talento humano, permitiéndoles abordar la innovación, la resolución de problemas y la implantación de nuevas tecnologías.
El Operador Virtual, junto con los módulos opConfig y opEvents, puede supervisar continuamente el rendimiento de la red, identificar posibles problemas y tomar medidas correctivas de forma proactiva. Este enfoque preventivo garantiza un rendimiento óptimo de la red, minimizando el tiempo de inactividad y maximizando la utilización de los recursos.
El Operador Virtual puede implantar y aplicar políticas de seguridad, detectar anomalías y responder a las amenazas a la seguridad en tiempo real. Este enfoque automatizado refuerza la seguridad de la red, mejora el cumplimiento de la normativa del sector y reduce el riesgo de brechas de seguridad.
Los operadores virtuales aprovechan enormes cantidades de datos de red para obtener información valiosa y optimizar las configuraciones de red. Esta información permite a los equipos de red tomar decisiones fundamentadas basadas en datos en tiempo real, lo que se traduce en una asignación de recursos y una optimización de la red más eficaces.
Caso práctico: Proveedores de servicios gestionados
Los proveedores de servicios gestionados (MSP) suelen gestionar simultáneamente las redes de varios clientes. Esta tarea puede requerir muchos recursos, sobre todo cuando se trata del mantenimiento rutinario y la resolución de problemas. El Operador Virtual ofrece una solución a este reto automatizando muchas de las tareas rutinarias que suelen realizar los MSP.
Por ejemplo, un MSP puede utilizar el Operador Virtual para automatizar el proceso de aplicación de parches de seguridad en varias redes de clientes. El Operador Virtual puede ejecutar los comandos necesarios para aplicar los parches, realizar pruebas para garantizar que los parches se han aplicado correctamente e informar de cualquier problema que surja. Esto no sólo reduce la carga de trabajo de los ingenieros del MSP, sino que también garantiza que los parches se apliquen de forma coherente y sin errores.
Caso práctico: Redes híbridas
El Operador Virtual simplifica la gestión de redes híbridas automatizando las tareas necesarias para mantener la conectividad y el rendimiento.
Por ejemplo, el Operador Virtual puede ajustar automáticamente las configuraciones de red para optimizar el rendimiento a medida que las cargas de trabajo cambian entre entornos locales y en la nube. También puede supervisar el tráfico de red para detectar posibles problemas y realizar ajustes en tiempo real para evitar interrupciones. Este nivel de automatización garantiza que las redes híbridas funcionen sin problemas y de forma eficiente, incluso cuando las condiciones cambian .
Cómo pueden las empresas ampliar la automatización de su red más allá del operador virtual
La adopción del Operador Virtual para la administración de redes representa un paso clave hacia el futuro de la automatización de redes para los equipos informáticos. Cómo puede una empresa ampliar la eficacia del Operador Virtual y qué novedades podemos esperar a medida que siga evolucionando la tecnología de automatización de redes?
El uso del Operador Virtual junto con otros módulos como opEvents, opTrend y Open-Audit impulsará una mayor automatización en la gestión de la red, lo que a la larga permitirá redes autorreparadoras capaces de identificar y resolver problemas sin intervención humana. Así se conseguirá una infraestructura de red más resistente, fiable y eficiente.
El uso del Operador Virtual para comprobar rutinariamente el estado de la red desempeñará un papel fundamental en el avance de la inteligencia de red, permitiendo a los equipos obtener una visión más profunda del rendimiento de la red, las amenazas a la seguridad y el comportamiento de los usuarios. Esto permitirá a los equipos tomar decisiones más informadas y optimizar sus redes de forma proactiva.
Con el tiempo, el uso de herramientas de automatización de redes como el Operador Virtual transformará el papel de los administradores e ingenieros de redes, desplazando su atención de las tareas rutinarias a actividades más estratégicas y creativas. Se implicarán más en el desarrollo de modelos de IA y la redacción de instrucciones, el análisis de datos y el diseño de soluciones de red inteligentes.
Conclusión
El Operador Virtual representa un importante paso adelante en la automatización de redes, aprovechando el poder de la IA para mejorar el rendimiento de la red, optimizar las operaciones y liberar recursos humanos para tareas más estratégicas. A medida que la IA y la automatización sigan avanzando, funciones como el Operador Virtual desempeñarán un papel cada vez más crucial para hacer posible una infraestructura de red más inteligente, eficiente y resistente.
Referencia:
Guía de mercado Gartner 2023 para la automatización de redes
https://www.gartner.com/en/documents/4913231

En un entorno de red moderno, la detección de activos informáticos es imprescindible.
Tener la capacidad de supervisar y gestionar los dispositivos de red le ayuda a proteger sus datos de usuarios no autorizados, mantener actualizados el software y los dispositivos críticos, lograr el cumplimiento de las normativas y mitigar las amenazas a la red. Además, ahorrará tiempo y recursos valiosos en tareas de exploración de la red y gestión de inventario.
Open-AudIT le permite hacer todas estas cosas y más en tiempo real, y puede tenerlo completamente instalado y funcionando en menos de 10 minutos. Le mostraremos cómo en esta guía rápida.
La herramienta de descubrimiento de redes de código abierto de FirstWave le muestra lo que hay en su red, cómo está configurada y cuándo cambia, para que usted pueda:
Open-AudIT lo hace escaneando de forma inteligente la red de su organización y almacenando las configuraciones de los dispositivos que descubre. Esto le proporciona una visibilidad inmediata de:
Open-AudIT también puede recopilar enormes cantidades de datos de distintas redes, que se pueden catalogar y cotejar en informes significativos. La descarga de esta herramienta no sólo es gratuita, sino que también ofrecemos una licencia profesional gratuita para 100 dispositivos con la que podrá empezar a trabajar.
El instalador de Open-AudIT se encargará de la mayoría de los requisitos previos por usted, pero asegúrese de que dispone de lo siguiente:
A continuación también se enumeran los requisitos previos específicos del sistema operativo. Obtenga más información sobre los requisitos para instalar y ejecutar Open-AudIT aquí.
Visite nuestro sitio web para descargar la última versión. Seleccione la opción Linux o Windows y descargue el binario.
Open-AudIT se instala en las instalaciones. También puede utilizar la máquina virtual FirstWave si lo prefiere, y obtener todas las aplicaciones de monitorización FirstWave instaladas y listas para usar.
Requisitos previos
Instalación
Obtenga más información sobre la instalación y actualización de Open-AudIT para Windows.
Requisitos previos
Instalación
Obtenga más información sobre la instalación y actualización de Open-AudIT para Linux.
¿Instalación para SUSE? Obtenga los detalles de la instalación aquí.
Open-AudIT puede gestionar diversos tipos de credenciales, incluidos los tipos estándar SNMP, Windows y SSH.
Si no dispone de las credenciales para un dispositivo de su red, seguirá viendo el dispositivo en Open-AudIT, pero la recuperación de datos será limitada.
Ahora, ¡puedes añadir un descubrimiento!
Después de añadir sus credenciales y ejecutar sus descubrimientos, observará que su panel de inicio muestra ahora una variedad de gráficos que le ofrecen una visión más profunda de su red.
¿Quieres ver cómo funciona? A continuación puedes ver todo el proceso con más detalle.
¡Feliz descubrimiento!
Lista de reproducción de Open-AudIT en YouTube

En la gestión de redes informáticas, es crucial mantener los servicios en funcionamiento y minimizar las interrupciones. Una forma importante de medir la eficacia de los gestores y operadores de redes en la resolución de problemas es el tiempo medio de resolución (MTTR).
El MTTR es un indicador clave de rendimiento utilizado en la gestión de redes para cuantificar el tiempo medio que se tarda en resolver un problema o interrupción de la red desde el momento en que se detecta.
Esta métrica abarca todo el proceso, desde la identificación inicial del problema (cuando un dispositivo como un enrutador, conmutador o servidor se cae o empieza a experimentar problemas) hasta el restablecimiento del servicio normal. El MTTR se calcula tomando el tiempo total empleado en resolver todas las incidencias en un periodo determinado y dividiéndolo por el número de incidencias.

En términos más sencillos, el MTTR proporciona una imagen clara del tiempo que su red está fuera de servicio durante un incidente típico y la rapidez con la que su equipo puede devolver todo a la normalidad. Es un reflejo de la eficiencia y eficacia de sus procesos de respuesta a incidentes.
El MTTR es más que un simple número; sirve como indicador directo de la salud de sus prácticas de gestión de red. He aquí por qué es tan crucial:
La definición de un "buen" MTTR puede variar en función del sector, la complejidad de la red y la naturaleza de los incidentes. Sin embargo, hay algunos puntos de referencia generales que los gestores de red pueden tener en cuenta:
El MTTR es una medida crítica que los gestores y operadores de redes deben supervisar y mejorar. Actúa como una señal clara de la rapidez con la que su equipo puede recuperarse de los problemas de la red, afectando a todo, desde la eficiencia operativa hasta la satisfacción del cliente. Al tratar de reducir el MTTR, los equipos de red no sólo mejoran la fiabilidad de su servicio, sino que también refuerzan su enfoque general de gestión de la red. En última instancia, un MTTR satisfactorio es aquel que cumple o supera las expectativas de su organización y de sus clientes, al tiempo que se esfuerza continuamente por lograr resoluciones más rápidas y eficaces.

Agilice la gestión del tráfico y aumente la eficiencia de su red con nuestra sencilla guía paso a paso para utilizar Secure Traffic Manager con NMIS.
En septiembre de 2023, FirstWave adquirió una empresa llamada Saisei, incluida su plataforma estrella, Secure Traffic Manager (STM), para la conformación del tráfico de red y la inspección profunda de paquetes.
Esta herramienta es un potente medio para que las telecos y las grandes empresas supervisen y gestionen el tráfico de red, permitiendo que determinadas aplicaciones o servicios tengan mayor calidad de servicio (QoS) que otros.
Utilizar STM tiene varias ventajas:
El uso de STM con la solución de gestión de red de código abierto de FirstWave, NMIS, le proporciona visibilidad y control totales sobre este tráfico, de modo que puede establecer reglas para automatizar la gestión del tráfico, orquestar alertas y mucho más.
Esta guía rápida le mostrará cómo monitorizar su dispositivo Saisei STM con NMIS.
En primer lugar, asegúrese de que NMIS está instalado y configurado correctamente en su entorno. Siga las instrucciones de instalación proporcionadas por FirstWave aquí. FirstWave ofrece una licencia gratuita de 20 nodos para empezar.
Active el protocolo SNMP (Simple Network Management Protocol) en su dispositivo STM. Configure los ajustes de SNMP, como las cadenas de comunidad y las versiones de SNMP, de acuerdo con sus políticas y requisitos de seguridad.
En NMIS, añada el dispositivo STM como dispositivo a supervisar. Deberá proporcionar la dirección IP o el nombre de host del dispositivo STM, las cadenas de comunidad SNMP y cualquier otro detalle de autenticación necesario.
Especifique qué parámetros y métricas desea supervisar en el dispositivo STM. Esto podría incluir cosas como el uso del ancho de banda, el tráfico de red o la utilización de la CPU y la memoria.
Defina niveles de umbral para los parámetros supervisados con el fin de activar alertas cuando se cumplan determinadas condiciones. Esto le permite gestionar de forma proactiva y responder a posibles problemas en el dispositivo STM.
Una vez configurado, pruebe su configuración de supervisión para asegurarse de que NMIS está recopilando correctamente los datos del dispositivo STM y que las alertas funcionan como se espera.
Revise y actualice periódicamente su configuración de supervisión según sea necesario. Esto garantiza que la supervisión siga siendo eficaz a medida que la red y la infraestructura evolucionan con el tiempo.
Ya está. Ahora puede obtener todos los beneficios de STM combinados con todos los beneficios de NMIS. A lo largo de este proceso, puede consultar la documentación de FirstWave para obtener orientación específica sobre la integración de los dispositivos STM con NMIS.
¿Necesita más ayuda? Póngase en contacto con el equipo de asistencia de FirstWave.