¿Pueden sus operaciones informáticas críticas sobrevivir a los escenarios "severos pero plausibles" de CPS 230?
¿Problemas con APRA CPS 230? Obtenga información práctica sobre la detección de activos, la supervisión de riesgos y la gobernanza de terceros para cumplir los requisitos de resistencia.
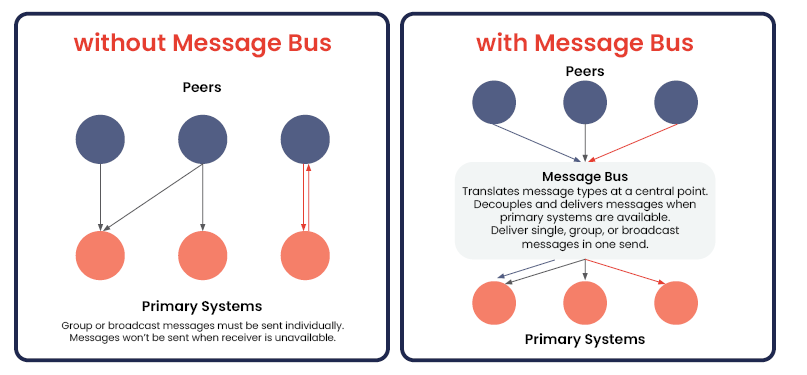
En Australia, la norma CPS 230 sobre gestión del riesgo operativo de la APRA entró en vigor el 1 de julio de 2025, sustituyendo a cinco normas existentes sobre externalización y continuidad de negocio y representando un cambio fundamental hacia una verdadera resistencia operativa para las instituciones financieras australianas. Aúna la externalización, la continuidad de la actividad y el riesgo operativo en una simple pregunta: ¿Pueden sus operaciones críticas sobrevivir a una interrupción grave pero plausible?
Esto incluye interrupciones en el entorno informático, problemas con los proveedores de servicios y cambios imprevistos en la infraestructura. Para los responsables de mantener los sistemas en funcionamiento, CPS 230 significa mayor visibilidad, una gobernanza más sólida de los proveedores de servicios y una respuesta más rápida cuando las cosas van mal.
Aunque este artículo se centra en la CPS 230 de la APRA, están surgiendo requisitos similares de resistencia operativa en todo el mundo, desde las normas de resistencia operativa de la PRA del Reino Unido hasta la Ley de Resistencia Operativa Digital (DORA) de la UE. Los mismos principios fundamentales de visibilidad de los activos, respuesta automatizada y supervisión de los proveedores de servicios se aplican con independencia de su marco normativo.
Qué significa esto en la práctica
Conozca lo que tiene y su estado de salud
No se puede gestionar lo que no se ve.
CPS 230 espera tener una imagen clara de su capacidad informática y del estado de sus activos.
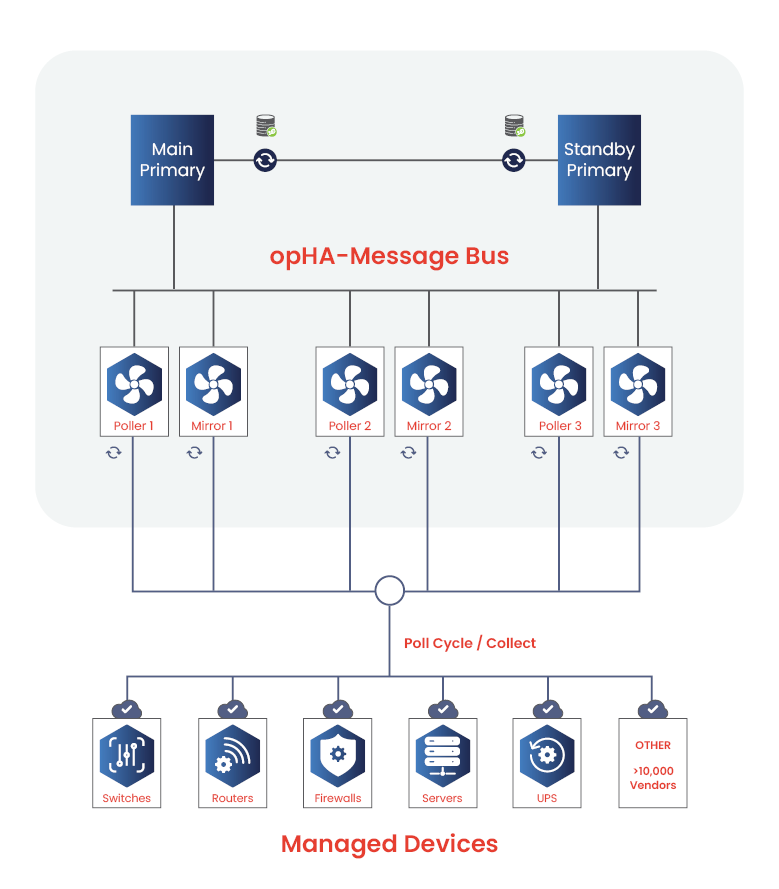
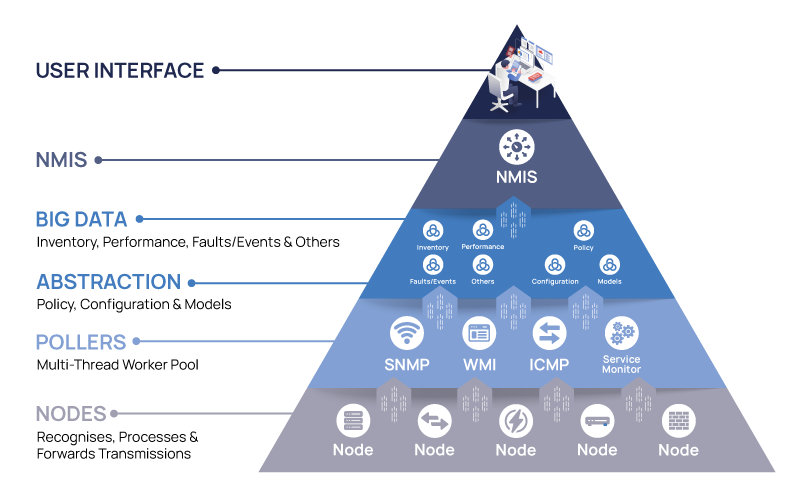
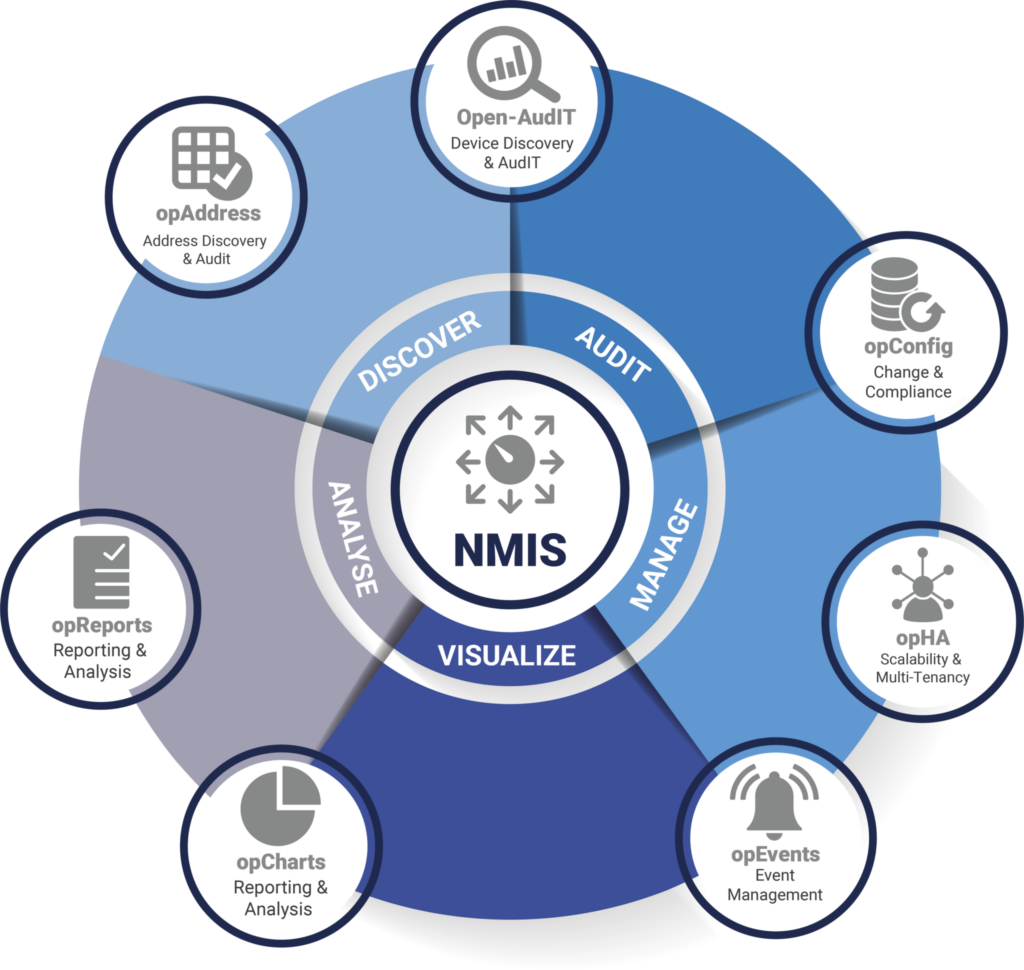
Open-AudIT descubre e inventaría automáticamente todos los dispositivos de su red (servidores, estaciones de trabajo y equipos de red) para que sepa qué hay, cómo está configurado y cuántos años tiene.
Combinado con OpConfig, puede realizar un seguimiento de los cambios y las configuraciones de referencia, detectando actualizaciones no autorizadas o inesperadas antes de que provoquen tiempos de inactividad.
Mayor supervisión de los proveedores de servicios
Muchos entornos dependen de equipos de TI subcontratados, integradores externos o proveedores de servicios gestionados. La norma CPS 230 exige una comprensión clara de quién accede a qué sistemas y establece procesos de recuperación cuando los proveedores de servicios se enfrentan a problemas. El énfasis de la norma en la "Gestión mejorada de riesgos de terceros" hace de la supervisión robusta de los proveedores de servicios un requisito fundamental.
Con OpCharts, puede crear portales de proveedores de servicios, permitiendo que equipos externos supervisen y gestionen únicamente los dispositivos y la infraestructura que usted autorice. Esto le proporciona transparencia de proveedor mientras mantiene el control de su entorno, apoyando las obligaciones contractuales que CPS 230 espera.
Vigilancia del riesgo operativo y respuesta rápida
Detectar los problemas a tiempo y saber cómo responder es fundamental para la resistencia. Como se destaca en el análisis de KPMG de la norma CPS 230, esta "sustenta la norma CPS 220 Gestión de riesgos" y exige a las organizaciones que demuestren que pueden mantener las operaciones críticas en situaciones de estrés.
OpEvents y el bus de mensajes de OpHA proporcionan gestión de eventos en tiempo real, alertándole de los problemas a medida que se producen y activando flujos de trabajo automatizados. Los operadores virtuales pueden incluso adoptar medidas correctivas de primera línea, desde el reinicio de servicios hasta la aplicación de correcciones conocidas, antes de que intervengan los humanos.
Preparación ante incidentes y recuperación automatizada
pregunta el CPS 230: ¿Qué ocurre si falla un sistema crítico? ¿Puede volver a funcionar dentro de los límites de tolerancia? La combinación de OpEvents para la detección y OpConfig para una rápida restauración o redistribución de la configuración significa que estará preparado para restaurar los servicios rápidamente. Los informes automáticos y las pistas de auditoría facilitan las revisiones posteriores a los incidentes y proporcionan a su junta directiva las pruebas que necesita para los informes APRA.
Aumento de la resistencia mediante controles de red y seguridad
Aunque la visibilidad de los activos y la corrección automatizada constituyen la base, la norma CPS 230 también exige controles preventivos y de continuidad en los servicios informáticos básicos. Esto se alinea con la integración de la norma con los requisitos de seguridad de la información CPS 234, donde la ciberresiliencia se convierte en un imperativo de cumplimiento.
Aquí es donde entra en juego el paquete de seguridad más amplio de FirstWave:
Secure Traffic Manager proporciona equilibrio de carga, conmutación por error y entrega segura de aplicaciones, garantizando que los servicios empresariales críticos permanezcan en línea incluso bajo carga o interrupción de la infraestructura.
CyberCision Email Security mantiene la resistencia de las comunicaciones bloqueando las amenazas maliciosas y no deseadas del correo electrónico que pueden interrumpir las operaciones empresariales o desencadenar incidentes.
CyberCision Web and Firewall Security protege los sistemas y datos críticos de ataques externos, garantizando la integridad de la red y apoyando una prestación de servicios continua y segura.
Estas soluciones abordan el énfasis de la norma en la prevención de incidentes, la respuesta rápida y la continuidad operativa, especialmente en escenarios en los que intervienen terceros o servicios alojados en la nube.
Cómo empezar
La visibilidad completa permite una seguridad y una gestión eficaces. Descubrir y definir las bases de su entorno sienta las bases de la resistencia CPS 230.
Descargue Open-AudIT y empiece a identificar todos los dispositivos conectados a su red. A partir de ahí, puede crear líneas de base, reforzar la supervisión de proveedores e incorporar supervisión, automatización y seguridad: todo lo que necesita para cumplir los requisitos de la norma CPS 230 y aumentar la confianza en su resistencia operativa.