Propósito
Este artículo proporcionará un ejemplo del uso de opEvents para activar opConfig para hacer un cambio operacional.
Caso práctico
Si una interfaz empieza a registrar errores de entrada, queremos desplazar automáticamente el tráfico fuera del circuito para mantener la calidad de la transmisión.
Páginas relacionadas
Antes de intentar esta configuración, el administrador debe estar familiarizado con los siguientes artículos de la wiki.
Resumen de la secuencia
- NMIS sondea un router con una consulta SNMP.
- El router devuelve un valor de contador de "error de entrada de la interfaz" que ha aumentado; activando así un umbral predefinido.
- NMIS genera una alerta de "error de entrada" que es procesada por opEvents.
- opEvents tiene una regla de acción predefinida que coincide con los errores de nodo, interfaz y entrada. Esta acción disparará un opConfig 'Conjunto de configuración'.
- El conjunto de configuración opConfig asociado aumentará el coste OSPF en las interfaces asociadas, haciendo que el router seleccione otra ruta si está disponible.
Configuración
NMIS
Por defecto NMIS tiene la configuración necesaria para alertar sobre los errores de entrada. Esto se hace con el sistema de umbrales de NMIS. Los umbrales para los diferentes niveles de alerta pueden ajustarse en la sección correspondiente de /usr/local/nmis8/models/Common-threshold.nmis. Los niveles siguientes representan un porcentaje de paquetes de error de entrada en comparación con los paquetes buenos.
/usr/local/nmis8/models/Common-threshold.nmis
'pkt_errors_in' => {
opEvents
Por defecto, opEvents procesa el registro de eventos NMIS. Todos los eventos son evaluados por /usr/local/omk/conf/EventActions.nmis. Si un evento coincide con una regla, se tomarán las acciones apropiadas. EventActions.nmis es también donde definimos los scripts que los opEvents pueden disparar. El primer paso es definir los scripts que cambiarán el tráfico de un enlace que está ejecutando errores de entrada. Como queremos desplazar todo el tráfico de este enlace, necesitaremos ejecutar scripts para ambos extremos del circuito. Fíjate en la referencia a un conjunto de configuraciones; éstas se definirán en la sección opConfig.
Los cambios en /usr/local/omk/conf/EventActions.nmis requieren que se reinicie el servicio omkd.
/usr/local/omk/conf/EventActions.nmis
'script' => {
Con los scripts definidos vamos a añadir la regla de coincidencia a la sección de políticas.
/usr/local/omk/conf/EventActions.nmis
'policy' => {
opConfig
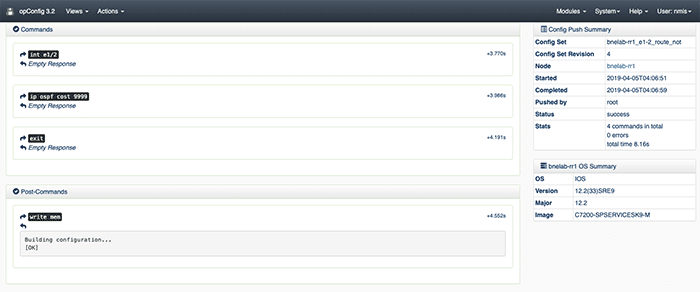
El siguiente paso es definir los conjuntos de configuración. Los conjuntos de configuración son conversaciones de opConfig para los comandos de configuración que te gustaría que se ejecutaran en el router. Debido a que este paso es complicado, pero muy repetible, he proporcionado este script: writeConfigSet.sh. Ejecuta el script y te pedirá los comandos que quieres que se ejecuten en el router e instalará el config set en opConfig. Para verificar los conjuntos de configuración utilice la GUI de opConfig, desde la barra de menú superior seleccione vistas, luego Visión General del Conjunto de Configuración.
Este es el aspecto de nuestro conjunto de configuración de ejemplo.
{
Pruebas y verificación
Generar errores de entrada
Hay varios tipos de errores de entrada, pero el más fácil de crear en un entorno de laboratorio son los gigantes. Esto se hace teniendo MTUs desiguales en ambos lados del mismo circuito; entonces se envían paquetes que son demasiado grandes desde el lado con la MTU más grande.