Gestionar un entorno grande y complejo con estados operativos siempre cambiantes es un reto, para ayudar, NMIS como un Sistema de Gestión de Red que está realizando la gestión del rendimiento y la gestión de fallos supervisa simultáneamente la salud y el estado operativo de los dispositivos y crea varias métricas individuales, así como una métrica global para cada dispositivo. Este artículo explica cuáles son esas métricas y qué significan.
Resumen
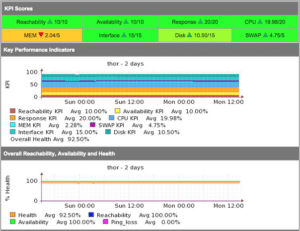
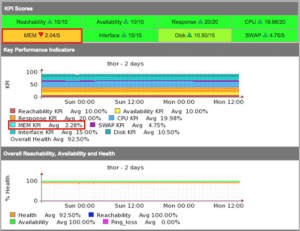
Considere esto en el contexto de que un dispositivo de red ofrece un servicio, el servicio que ofrece es la conectividad, mientras un router o un conmutador está en funcionamiento y todas las interfaces están disponibles, está realmente en funcionamiento, y cuando no tiene carga de CPU está sano, a medida que las interfaces se utilizan y la CPU está ocupada, tiene menos capacidad restante. Las siguientes estadísticas se consideran parte de la salud del dispositivo:
- Capacidad de alcance: si está arriba o no;
- Disponibilidad: disponibilidad de la interfaz de todas las interfaces que se supone que están activas;
- Tiempo de respuesta;
- CPU;
- La memoria;
Todas estas métricas se ponderan y se crea una métrica de salud. Esta métrica, cuando se compara a lo largo del tiempo, debería indicar siempre la salud relativa del dispositivo. Las interfaces que no se utilicen deben cerrarse para que la métrica de salud siga siendo realista. Los cálculos exactos se pueden ver en la subrutina runReach en nmis.pl.
Detalles métricos
Mucha gente quería la disponibilidad de la red y muchas herramientas generaban la disponibilidad basándose en las estadísticas de ping y afirmaban que era un éxito. Esto, sin embargo, era una mala solución, por ejemplo, el conmutador que ejecutaba el servidor de gestión podía estar caído y el servidor de gestión informaría de que toda la red estaba caída, lo que por supuesto no era así. O peor aún, un dispositivo podría responder a un PING pero muchas de sus interfaces estaban caídas, por lo que aunque era alcanzable, no estaba realmente disponible.
Así, se determinó que NMIS utilizaría Reachability, Availability y Health para representar la red. La alcanzabilidad es la capacidad de ping del dispositivo, la disponibilidad es (en el contexto de los equipos de red) las interfaces que deberían estar activas, estén o no activas, por ejemplo, las interfaces que son "no shutdown" (ifAdminStatus = up) deberían estar activas, por lo que un dispositivo con 10 interfaces de ifAdminStatus = up y ifOperStatus = up para 9 interfaces, el dispositivo estaría disponible en un 90%.
La salud es una métrica compuesta, formada por muchas cosas dependiendo del dispositivo, router, CPU, memoria. Algo interesante aquí es que parte de la salud se compone de un inverso de la utilización de la interfaz, por lo que una interfaz que no tiene ninguna utilización tendrá un alto componente de salud, una interfaz que está muy utilizada reducirá esa métrica. Así que la salud es un reflejo de la carga en el dispositivo y será muy dinámica.
La métrica global de un dispositivo es una métrica compuesta formada por valores ponderados de las otras métricas que se recogen. La fórmula para esto es configurable, por lo que puedes ponderar la Reachability para que sea más alta de lo que es actualmente, o más baja, a tu elección.
Disponibilidad, ifAdminStatus y ifOperStatus
La disponibilidad es la disponibilidad de la interfaz, que se refleja en la métrica SNMP ifOperStatus si una interfaz es ifAdminStatus = up y el ifOperStatus = up que es el 100% para esa interfaz si un dispositivo tiene 10 interfaces y todas son ifAdminStatus = up y el ifOperStatus = up que es el 100% para el dispositivo
Si un dispositivo tiene 9 interfaces ifAdminStatus = up y el ifOperStatus = up y 1 interfaz ifAdminStatus = up y el ifOperStatus = down, es decir el 90% de disponibilidad es la disponibilidad de los servicios de red que ofrece el router/switch
Configuración de las ponderaciones de las métricas
En la configuración de NMIS, Config.nmis hay varios elementos de configuración para el estos son los siguientes:
'metrics' => {
'weight_availability' => '0.1',
'weight_cpu' => '0.2',
'weight_int' => '0.3',
'weight_mem' => '0.1',
'weight_response' => '0.2',
'weight_reachability' => '0.1',
'metric_health' => '0.4',
'metric_availability' => '0.2',
'metric_reachability' => '0.4',
'average_decimals' => '2',
'average_diff' => '0.1',
},
La métrica de salud utiliza elementos que empiezan por "weight_" para ponderar los valores en la métrica de salud. La métrica global combina la salud, la disponibilidad y la accesibilidad en una sola métrica para cada dispositivo y para cada grupo y, en última instancia, para toda la red.
Si hay que dar más peso a la utilización de la interfaz y menos a la disponibilidad de la misma, estas métricas pueden ajustarse, por ejemplo, peso_disponibilidad podría ser 0,05 y peso_int podría ser 0,25, los pesos resultantes (peso_*) deberían sumar 100.
Otras opciones de configuración de las métricas
En NMIS 8.5.2G se han introducido algunas opciones de configuración adicionales para ayudar a que todo esto funcione, y para hacerlo más o menos sensible. Las dos primeras opciones son metric_comparison_first_period y metric_comparison_second_period, que son por defecto -8 horas y -16 horas.
Estas son las dos variables principales que controlan las comparaciones que se ven en NMIS, el baseline de salud en tiempo real. Estas dos opciones serán los cálculos realizados desde el tiempo actual hasta el tiempo de metric_comparison_first_period (hace 8 horas) hasta los cálculos realizados desde metric_comparison_first_period (hace 8 horas) hasta metric_comparison_second_period (hace 16 horas).
Esto significa que NMIS está comparando en tiempo real los datos de la última hora 8 horas con el período de 8 horas anterior. Usted puede hacer esto más pequeños o más largos períodos de tiempo. En el laboratorio estoy corriendo -4 horas y -8 horas, lo que hace que las métricas un poco más sensible a la carga y el cambio.
La otra nueva opción de configuración es metric_int_utilisation_above que es -1 por defecto. Esto significa que las interfaces con una utilización de 0 (cero) se contabilizarán en las métricas globales de utilización de la interfaz. Por lo tanto, si tiene un conmutador con 48 interfaces activas pero básicamente sin utilización y dos enlaces ascendentes con una carga del 5 al 10%, la utilización media de las 48 interfaces es muy baja, por lo que ahora elegimos la utilización más alta de entrada y salida y sólo añadimos las interfaces con una utilización superior a esta cantidad configurada, el ajuste a 0,5 debería producir métricas de salud más dinámicas.
Ejemplos de cálculos métricos
Ejemplo de salud
Al finalizar un ciclo de sondeo para un nodo, algunas métricas de salud que han sido almacenadas en caché están listas para calcular la métrica de salud de un nodo, así que digamos que los resultados para un router fueron:
- CPU = 20%.
- Disponibilidad = 90%.
- Utilización de todas las interfaces = 10%.
- Memoria libre = 20%.
- Tiempo de respuesta = 50ms
- Capacidad de alcance = 100 %.
El primer paso es que los valores medidos son ponderados para que puedan ser comparados correctamente. Así, si la carga de la CPU es del 20%, el peso para el cálculo de la salud se convertirá en el 90%, si el tiempo de respuesta es de 100ms se convertirá en el 100%, pero un tiempo de respuesta de 500ms se convertiría en el 60%, hay una subrutina weightResponseTime para este cálculo.
Así que los valores ponderados pasarían a ser:
- CPU ponderada = 90%
- Disponibilidad ponderada = 90% (no requiere ponderación, ya está en % donde el 100% es bueno)
- Utilización ponderada de la interfaz = 90% (100 menos la utilización total real de la interfaz)
- Memoria ponderada = 60%.
- Tiempo de respuesta ponderado = 100 %.
- Alcanzabilidad ponderada = 100% (no requiere ponderación, ya está en % donde el 100% es bueno)
NB. En el caso de los servidores, el peso de la interfaz se divide por dos y se utiliza por igual para la utilización de la interfaz y el disco libre.
Estos valores se incluyen ahora en el cálculo final:
weight_cpu * 90 + weight_availability * 90 + weight_int * 90 + weight_mem * 60 + weight_response * 100 + weight_reachability * 100
que se convierte en "0,2 * 90 + 0,1 * 90 + 0,3 * 90 + 0,1 * 60 + 0,2 * 100 + 0,1 * 100" dando como resultado un 90% para la métrica de salud
The calculations can be seen in the collect debug, nmis.pl type=collect node=<NODENAME> debug=true
09:08:36 runReach, Starting node meatball, type=router
09:08:36 runReach, Outage for meatball is
09:08:36 runReach, Getting Interface Utilisation Health
09:08:36 runReach, Intf Summary in=0.00 out=0.00 intsumm=200 count=1
09:08:36 runReach, Intf Summary in=0.06 out=0.55 intsumm=399.39 count=2
09:08:36 runReach, Intf Summary in=8.47 out=5.81 intsumm=585.11 count=3
09:08:36 runReach, Intf Summary in=0.00 out=0.00 intsumm=785.11 count=4
09:08:36 runReach, Intf Summary in=0.06 out=0.56 intsumm=984.49 count=5
09:08:36 runReach, Intf Summary in=0.00 out=0.00 intsumm=1184.49 count=6
09:08:36 runReach, Intf Summary in=8.47 out=6.66 intsumm=1369.36 count=7
09:08:36 runReach, Intf Summary in=0.05 out=0.56 intsumm=1568.75 count=8
09:08:36 runReach, Calculation of health=96.11
09:08:36 runReach, Reachability and Metric Stats Summary
09:08:36 runReach, collect=true (Node table)
09:08:36 runReach, ping=100 (normalised)
09:08:36 runReach, cpuWeight=90 (normalised)
09:08:36 runReach, memWeight=100 (normalised)
09:08:36 runReach, intWeight=98.05 (100 less the actual total interface utilisation)
09:08:36 runReach, responseWeight=100 (normalised)
09:08:36 runReach, total number of interfaces=24
09:08:36 runReach, total number of interfaces up=7
09:08:36 runReach, total number of interfaces collected=8
09:08:36 runReach, total number of interfaces coll. up=6
09:08:36 runReach, availability=75
09:08:36 runReach, cpu=13
09:08:36 runReach, disk=0
09:08:36 runReach, health=96.11
09:08:36 runReach, intfColUp=6
09:08:36 runReach, intfCollect=8
09:08:36 runReach, intfTotal=24
09:08:36 runReach, intfUp=7
09:08:36 runReach, loss=0
09:08:36 runReach, mem=61.5342941922784
09:08:36 runReach, operCount=8
09:08:36 runReach, operStatus=600
09:08:36 runReach, reachability=100
09:08:36 runReach, responsetime=1.32
Ejemplo métrico
Los cálculos métricos son mucho más sencillos, estos cálculos se realizan en una subrutina llamada getGroupSummary en NMIS.pm, para cada nodo la disponibilidad, la alcanzabilidad y la salud se extraen del archivo RRD "reach" de los nodos, y luego se ponderan de acuerdo con los pesos de la configuración.
Así, basándonos en nuestro ejemplo anterior, el nodo tendría los siguientes valores:
- Salud = 90%
- Disponibilidad = 90%.
- Capacidad de alcance = 100 %.
La fórmula pasaría a ser, "métrica_salud * 90 + métrica_disponibilidad * 90 + métrica_alcance * 100", dando como resultado "0,4 * 90 + 0,2 * 90 + 0,4 * 100 = 94", Por lo tanto, una métrica de 94 para este nodo, que se promedia con todos los demás nodos de este grupo, o de toda la red para dar como resultado la métrica de cada grupo y de toda la red.




")


")