18 May 2016
System Automation Through Integration

I have the pleasure of working with dozens of engineers every month from companies all over North America. No matter the type of business they work for I have found they all have one thing in common – they’re all trying to maintain larger and more complex networks with a smaller team of staff.
Network management systems strive to automate the user experience, from the implementation of complex scheduling systems to the use of heuristics engines to assist with event handling. The one piece that is often missing is the maintenance of the monitoring solution itself. Recently Opmantek had the opportunity to address this issue head-on. What we did, how it works, and the results we achieved are the subject of this article.
Like many North American businesses, our client, a large multinational corporation, had grown over the years through several mergers and acquisitions. Their infrastructure management consisted of several disparate platforms from more than a dozen vendors.
Our implementation services include a series of up-front workshops designed to elicit information and feedback from all levels; engineer to upper management. When we conducted these investigative meetings we discovered many challenges and pain points specifically to our client’s business. We also learned that they had Service Now – a configuration management database (CMDB) – that was being used as the company’s single source of truth for all equipment inventory. This gave us an idea…
Service Now, like most modern CMDB systems, includes a very robust application programming interface (API). Using this API we were easily able to create an integration which would pull a list of active devices, compare them to the devices currently being monitored, and reconcile the list by adding new devices, updating existing devices, and even retiring devices from monitoring when they were marked as out of service.
Our architectural solution for this client included a series of geographically diverse polling engines all rolling-up to a series of redundant primary servers. Each layer offering multiple methods of redundancy and failover. Our integration with Service Now accounted for this, automating the assignment of devices to polling engines geographically, even supporting devices with different service levels; some need 1 or 2 assigned polling engines.
To further enhance the system, we also automated the assignment of devices to opConfig, our Configuration and Compliance Management solution and opEvents, our intelligent event management system which provides event correlation, deduplication, and action automation. These solutions were then complemented by the addition of opTrend, which expands on Opmantek’s already expansive thresholding and alerting system by implementing a highly flexible Statistical Exception Detection System (SEDS), Igor Trubin’s methodology, that learns what’s normal behavior on the client’s network and adjusts thresholding dynamically based on historical usage for every hour of each day of the week.
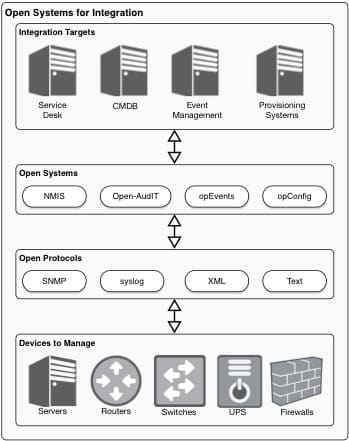
Our Phase 1 implementation focused on network devices and have allowed the client to consolidate their monitoring platform to a single Opmantek based solution, decommissioning several other systems. In our next Phase, we will be automating the monitoring of their expansive server network. This effort will continue to leverage the information in Service Now; allowing us to monitor services and applications, generate synthetic transactions to exercise each application tier, and continue to expand their view across the enterprise through a single pane of glass.
The last piece of this puzzle was the addition of Service Assurance and Monitoring. This provides an additional layer of support through monthly server checks, software upgrades, and 24/7 monitoring of the monitoring solution. With these solutions in place the client needn’t worry that they will miss an event because their monitoring solution wasn’t up-to-date or worse, wasn’t functioning as designed.
In all, Opmantek’s integrated solution has now removed the maintenance needed to maintain most network monitoring systems, ensured all devices are properly monitored to the correct SLA and delivered an enterprise-class solution through a single pane of glass.